Permutations: Replacing the block cipher?
History
For the past few decades, the block cipher has been the primary symmetric cryptographic primitive. Aside from the odd stream cipher (primarily RC-4), pretty much every common cryptographic primitive from before 2010 can be seen as built from a block cipher.
Quick note: How do we define a block cipher? A block cipher is a function with the form c = f(p, k) where c, p are an N-bit ciphertext and plaintext respectively, and k is an M-bit key.
That this is the case with ciphers like DES and AES is obvious - these are firmly classified as block ciphers. But with the other major family of cryptographic functions - hash functions - are built in the same way is less so. This involve looking at how these are built, and in the case of the prolific MD4 family (which comprises MD5, SHA-1, RIPEMD-160, and the SHA-2 hash functions), they are all built upon the Merkle–Damgård construction

The MD construction takes a compression function and iterates it once per input block of data (additionally, because the compression function takes a fixed amount of input on each iteration, it is necessary to pad the last block. The way this is done varies between hash functions, but in general most deterministic types of block cipher padding work).
What’s a compression function? Its a function which takes the form s2 = f(s1, b) where s1 is an N-bit input state, s2 is an N-bit output state, and b is B-bit input. You may notice that this looks a lot like a block cipher, and you’d be right: An MD hash is an odd use of a block cipher where you feed the data in through the key input.
This isn’t merely an observation though: There are two notable sets of algorithms which are based upon this result:
- MDC-2 isn’t quite a Merkle–Damgård construction, in part becuase it’s being used to turn an N-bit blockcipher into a 2N-bit hash function, but it too produces a one-way compression function out of a block cipher by feeding the input in as the “key”
- SHACAL SHACAL extracts the block cipher out of SHA-1 and SHA-2 as distinct algorithms (in the case of SHACAL-1, this produces a cipher with a decidedly odd 160-bit block size)
Side note: MDC-2 is a simple design with a strong proof of security. If you ever find yourself writing code for a low performance embedded platform with an AES accelerator, and need a hash function, using MD-2 to produce a 256-bit hash function out of AES would not be a bad call
The Merkle–Damgård construction has stood the test of time, and the SHA-2 family is handling the test of time well. However, it does have one major flaw in the form of length extension attacks: Most MD hashes - and indeed all of the ones commonly used here - use the final state (after inputting the last block of data and padding) as the hash value with no modification. A consequence of this is that if you give me the hash of a message M H(m), I can initialise the internal state of my hash function to that value and compute the hash of any extended message H(m || Pad(m) || n) (where Pad(m) is the hash function’s internal padding for message m, and || is its useful sense in cryptography-related texts: conatenation)
This is why HMAC exists: If you compute H(k || m), any attacker can compute H(k || m || Pad(k || m) || n) and impersonate you. New hash functions - like BLAKE and SHA-3 are not vulnerable to such attacks.
Its relatively easy to avoid such attacks with MD construction though, via either of two methods:
- You can add a non-invertible finalisation step, so that the output doesn’t directly match the internal state, or
- You can drop a some of the state from the output data, so the attacker doesn’t have the entirety of it. NIST defined SHA-512/256 and SHA-512/224 as official truncated versions of SHA-512 (with different initialization values, so a SHA-512 hash directly truncated doesn’t produce the same values) to defend against this in 2012. SHA-384 and SHA-224, being similarly truncated versions of SHA-512 and SHA-256 also offer some defense against this, albeit with lower margins (128-bit in the case of SHA-384, and only 32-bit in the case of SHA-224)
However, block ciphers in general are going out of style, and in their place permutations are becoming the common building block
Permutations
A permutation is a function o = f(i), where o and i are N-Bit output and inputs. A permutation might have an inverse function, but it’s not strictly a requirement (in the same way as it’s not strictly a requirement of the compression function used inside an MD hash funciton either).
Most modern cryptographic building blocks have permutations at their core:
- Salsa20 and Chacha20 functions are both permutations, taking 64-byte inputs and producing 64-byte outputs.
- The BLAKE family of hash functions (derived from Chacha20) are also built around a 64-byte permutation
- SHA-3 is built around the 1600-bit Keccak permutation and the Sponge construction
- The Gimli lightweight cryptography function is also defined as a 384-bit permutation
It’s relatively easy to derive a stream cipher from a permutation: Feed it, as inputs
- An optional constant
- The secret key
- The Initilaization Vector / Nonce
- The block counter
and use the resulting output as your keystream; this is how the Salsa20/Chacha20 family of ciphers work. But it’s also possible to derive other functions, some of them very interesting
One thing of note before we progress: The following constructions divide the state of an N-Bit permutation into two parts:
r, the rate, which controls the number of bits of input consumed and/or output produced per iterationc, the capacity, which controls the security level. Roughly acbit capacity produces ac/2bit security level, but the details for each particular construction vary
Sponges: Hashes and “Extensible Output Functions”

The Sponge Construction is named after its real life counterpart: During the first phase, the sponge absorbs its input; then, during the second, output is “squeezed” out of it. You initialise your state to some value (typically zero) and then, at each step, XOR N bytes of the input into it before applying the permutation.
At the end, instead of adding N bytes to the state, you extract N bytes out of it in each cycle before applying the permutation to mix the state around.
This comes with some advantages: Because only some of the state is extracted at each output step, length extension attacks are impossible. Additionally, you can keep squeezing ad-infinitum, which gives you an extensible output function. These don’t give you output with any more collision resistance than the hash operated normally, but can be used when you need a specific number of bits of output.
This means that from the permutation, using the sponge construction we can already derive
- A hash function: Insert the input data, then extract N bits of output
- A MAC: Trivially by just computing
H(K || M), though there are better and only slightly more complicated methods - A key material “extractor” (in the same sense as HKDF-Extract: A function which takes as input a variable amount of input, and produces a fixed amount of output suitable for use as a key)
- A key material “expander” (also in the same sense as HKDF-Expand: A function which takes a fixed input key and a domain separation label, and produces a variable amount of output)
- A stream cipher: As well as the method of construction used by Chacha20
But this isn’t the only thing a Sponge can do
AEADs: Duplexing the permutation
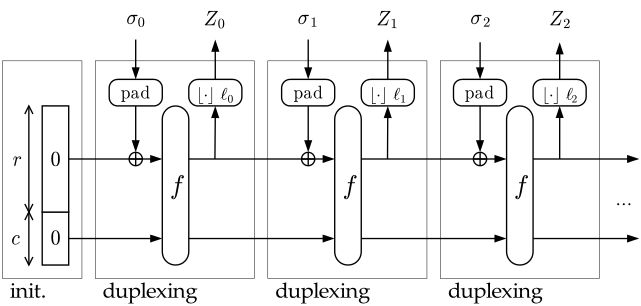
What if
- Before encrypting any data, we inserted our secret key into the state in the same way as we did for the Sponge function above,
- We XOR in an IV in a similar way, and
- After we XOR each input block into the state (but before we run the permutation function), we output that as ciphertext?
In doing so, we’ve produced something that looks a bit like the CFB (ciphertext feedback) block cipher mode; the recipient can XOR a block of ciphertext against the state of the sponge to recover the plaintext. However, a replacement for CFB mode is fairly uininteresting: even with a block cipher, there’s little reason to use it instead of counter mode.
But if we added an additional step:
- Once we’ve inserted all the data into the state and run the permutation function, we extract N-bits of data as a MAC
People have tried doing similar things with block ciphers; for example, encrypt a block of zeroes at the end of the data in CBC mode, verify its still zero on decryption, but these are doomed to failure (modifying a block of ciphertext in CBC mode only affects that block and the following one); however, this isn’t the case when we’re using a permutation as our primitive because there’s a whole bunch of state in our permutation which an attacker never sees.
So if we’re building off of a permutation, we can produce ourselves an AEAD without needing a separate primitive for the authentication part (such as Poly1305 or GCM’s GHash)
Note: In common with most traditional AEAD constructions, this construction isn’t nonce-misuse resistant. If you wish nonce-misuse resistance, you will likely need to use a two-pass construction such as constructing a synthetic IV from a hash of the IV and the message
Building on top of the Duplex
We can build other things on top of this primitive as well; one of the examples given in the Sponge paper is a reseedable pseudorandom number generator. Indeed, the NetBSD random number generator is now built upon a Keccak sponge
Indeed, both duplex and sponge constructions are very flexible: there’s no reason to limit them to a single pass of data input or output. It would be entirely reasonable for a stream protocol (such as TLS, though not DTLS) to initialise a cipher state and then keep reusing that same state to encrypt and authenticate each message sent.
The Future?
Will the block cipher die? I doubt it - if only because of inertia. Additionally, there are a few applications (mostly where there are very small amounts of constant size data to encrypt) where a block cipher in ECB mode is the best primitive.
But it definitely seems like we’ve passed a turning point, and permutations are the way we’re going to be doing cryptography into the future.